

Stability AI, in collaboration with its multimodal AI research lab DeepFloyd, has announced the research release of DeepFloyd IF, a cutting-edge text-to-image model. The model is designed to provide researchers with the opportunity to explore and experiment with advanced text-to-image generation approaches. DeepFloyd IF is initially released under a research license, with plans to release a fully open-source version in the future.
DeepFloyd IF is a modular, cascaded, pixel diffusion model that generates high-resolution images using a three-stage process. The model is built with multiple neural modules, each solving independent tasks, and working together within a single architecture to create a synergistic effect. The model's base and super-resolution models adopt diffusion models, making use of Markov chain steps to introduce random noise into the data before reversing the process to generate new data samples from the noise.
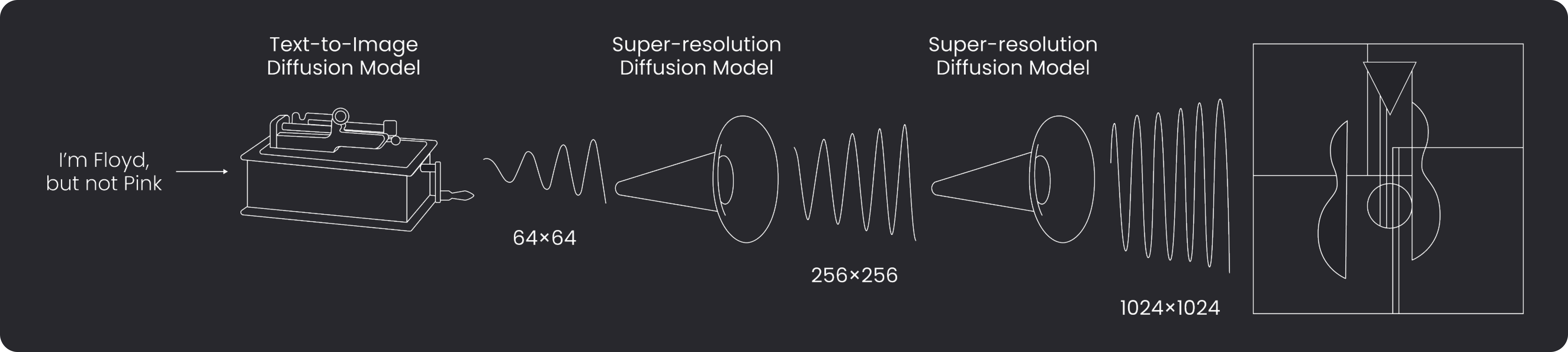
DeepFloyd IF employs the large language model T5-XXL as a text encoder, achieving deep text prompt understanding. The model uses optimal attention pooling and additional attention layers in super-resolution modules to extract information from text, resulting in coherent and clear text integration alongside objects in images.
The model achieves a high degree of photorealism, reflected by its impressive zero-shot FID score of 6.66 on the COCO dataset. The IF-4.3B base model, the largest diffusion model in terms of the number of effective parameters of the U-Net, outperforms existing models such as Imagen and eDiff-I, setting a new benchmark in the field.
DeepFloyd IF can perform image-to-image translations by resizing the original image, adding noise via forward diffusion, and de-noising the image with a new prompt during the backward diffusion process. This approach allows for modifying style, patterns, and details in the output while preserving the essence of the source image, all without the need for fine-tuning.

The model excels in creative use cases, such as embroidering text on fabric, inserting text into stained-glass windows, including text in collages, and lighting up text on neon signs. These use cases have been challenging for most text-to-image models until now.
DeepFloyd IF was trained on a custom high-quality LAION-A dataset that contains 1 billion (image, text) pairs. The dataset underwent deduplication, extra cleaning, and other modifications to ensure quality.
Stability AI's press release highlights the potential of DeepFloyd IF, stating, "We believe that the research on DeepFloyd IF can lead to the development of novel applications across various domains, including art, design, storytelling, virtual reality, accessibility, and more. By unlocking the full potential of this state-of-the-art text-to-image model, researchers can create innovative solutions that benefit a wide range of users and industries."
The company has posed several research questions for the academic community, including exploring the role of pre-training for transfer learning, enhancing the model's control over image generation, and assessing the model's interpretability. Ethical research questions include addressing biases in the model, its impact on social media, and the development of fake image detectors.
DeepFloyd IF is available for access on Deep Floyd's Hugging Face space, and additional information can be found on the model's website.





