

Google DeepMind's latest research on large language models (LLMs) provides compelling evidence that these AI systems can exceed human performance when it comes to fact-checking long-form content. The findings, detailed in a new paper, mark a significant milestone in the development of more truthful and reliable AI.
The study introduces LongFact, a benchmark dataset comprising thousands of fact-seeking questions across 38 topics, generated using GPT-4. To evaluate the factual accuracy of LLM responses to these questions, the researchers propose the Search-Augmented Factuality Evaluator (SAFE). This method uses an LLM to break down a long-form response into individual facts, queries Google Search to find supporting evidence for each fact, and determines the overall factuality of the response through multi-step reasoning.
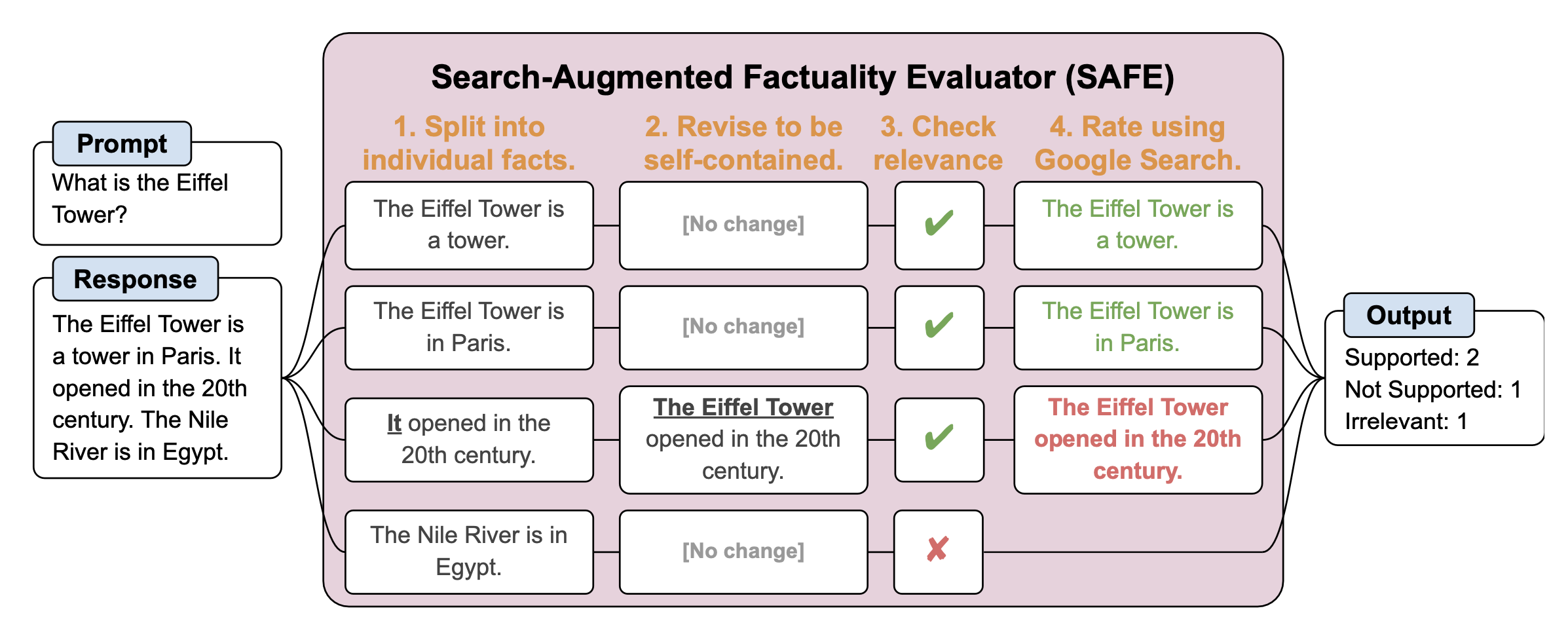
Here are the key findings:
- LLM agents can achieve superhuman performance on fact-checking when given access to Google Search. SAFE agreed with human annotators 72% of the time on a set of approximately 16,000 individual facts. For a random subset of 100 disagreement cases, SAFE was correct 76% of the time.
- Larger language models generally achieve better long-form factuality. The study benchmarked 13 models across four families (Gemini, GPT, Claude, and PaLM-2) and found that model size correlates with factual accuracy.
- Automated fact-checking with LLMs is significantly more cost-effective than human annotation. SAFE is more than 20 times cheaper than using crowdsourced human annotators.
The researchers also propose extending the F1 score as an aggregated metric for long-form factuality. This metric, called F1@K, balances the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter K, which represents a user's preferred response length (recall).
While the study demonstrates the potential of LLMs as highly capable fact-checkers, the authors acknowledge some limitations. SAFE relies on the underlying LLM's capabilities and the comprehensiveness of Google Search results. Additionally, the proposed F1@K metric assumes no repetition of facts in the model's response.
Despite these caveats, the research presents a promising step towards more truthful AI systems. As LLMs continue to improve, their ability to assess and ensure the factual accuracy of generated text could have far-reaching implications for combating misinformation and increasing trust in AI applications.
Google has released the original code for the paper on GitHub.