

Meta has unveiled a new AI model called Emu (Expressive Media Universe) that can generate incredibly realistic and aesthetically pleasing images from text captions. The key innovation behind Emu is a technique called "quality tuning" that dramatically enhances the visual appeal of images produced by AI text-to-image models.
In their paper, Meta AI researchers detail how they pre-trained a latent diffusion model using a massive dataset of 1.1 billion image-text pairs, then fine-tuned the system on just 2000 carefully curated, high-quality images. This small set of "photogenic needles in a haystack" proved surprisingly effective at guiding the AI system to generate images adhering to professional photographic principles for composition, lighting, color, focus and more.
For many, it might seem counterintuitive: why would quantity not be the primary goal in fine-tuning datasets? The answer, as the researchers argue, lies in the subjective and elusive realm of aesthetics. While 'beauty' in art remains a fiercely debated topic, the paper posits that when training AI models to generate images, quality has an unparalleled influence. This insight forms the heart of their endeavors.
The approach Meta took to curate their dataset is a combination of modern technology and the irreplaceable human touch. Initially, they cast a wide net, harvesting billions of images, which they then refined using a series of automatic filters. These filters screened for factors like offensive content, image-text alignment, and even the sheer number of overlaying texts on the images.
However, automatic filtering could only take them so far. This is where human intervention became indispensable. Annotators, both generalists and specialists, were brought on board to sift through the images, ensuring that only the crème de la crème - those that are not just good but exceptional - made the cut. At the end of the filtering process, they retained only 2000 "exceptionally high-quality images".

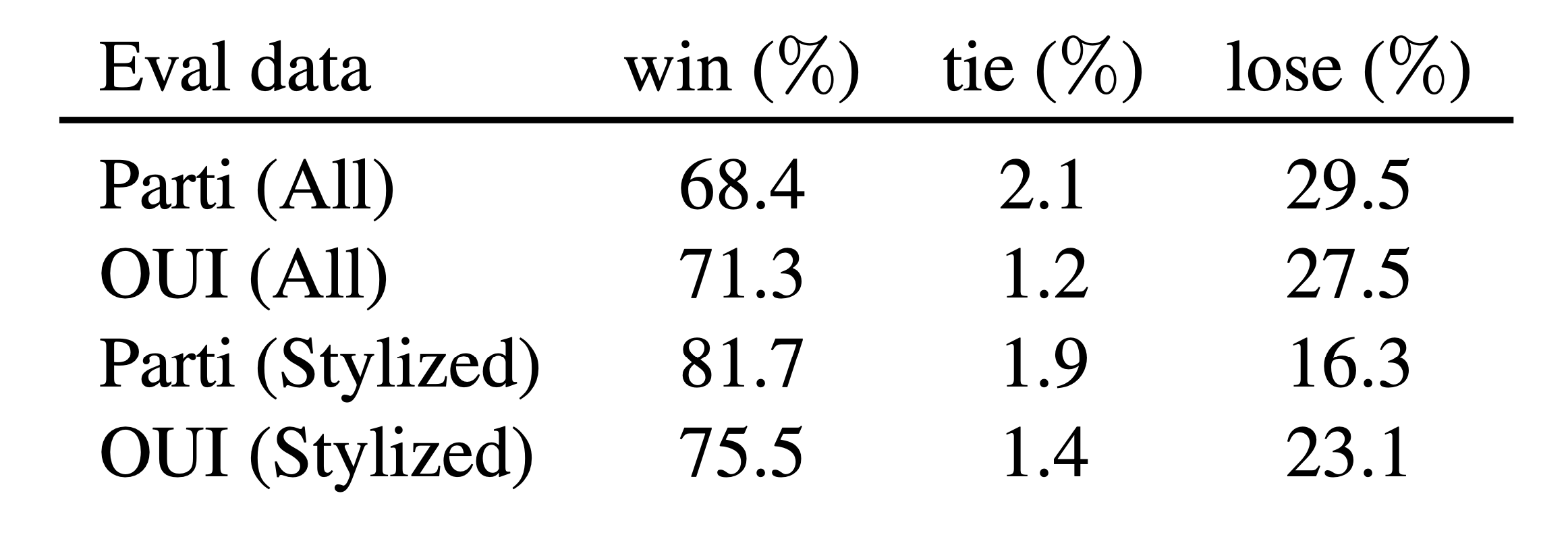
The researchers dubbed this quality-tuned model 'Emu', a nod to the distinctive, attention-grabbing nature of the bird it's named after. Using two expansive sets of prompts - PartiPrompts and their own Open User Input benchmark based on real world usage - the researchers gauged the performance of Emu against its pre-trained counterpart. The results were overwhelmingly in favor of Emu, especially in terms of visual appeal and text faithfulness. Side-by-side comparisons show Emu creates images with far more vivid colors, balanced lighting, compelling subjects and aesthetic flair.
The fact that Emu outperformed its predecessor wasn't merely a testament to its efficiency but a ringing endorsement of the entire research methodology. Even in non-photorealistic settings like sketches or cartoons, Emu's superiority shone through.
Meta also compared Emu to the state-of-the-art SDXL1.0 model and found that Emu is preferred 68.4% of the time on visual appeal on the standard PartiPrompts benchmark and 71.3% on their Open User Input benchmark.
Meta researchers attribute this performance jump not just to the model architecture, but crucially to the quality and diversity of data used for fine-tuning. They found that with as few as 100 high-quality training images, Emu's generation improved markedly. This suggests that for aligning AI creativity with human aesthetics, a small set of exquisite examples can go a long way.

Emu also retains the versatility to depict diverse concepts, from portraits to landscapes to abstract art. Emu represents a big step for Meta towards AI that can turn ideas into beautiful visual content. It highlights the value of curation in ML datasets and foreshadows a future where text alone may suffice to illustrate our imagination. Emu functionality will be accessible via the Meta AI chatbot across various apps and devices.