

Stability AI has released Stable LM 2 1.6B, the first model in their new series of multilingual language models. Its small size, multilingual capabilities, and strong performance across a variety of natural language tasks makes it a valuable tool for developers.
The model was pre-trained on 2 trillion tokens of a filtered mixture of open-source, large-scale datasets (supplemented with multi-lingual data from CulturaX) on 512 NVIDIA A100 40GB GPUs (AWS P4d instances). It fluently handles English, Spanish, German, Italian, French, Portuguese, and Dutch. Stability AI says the model architecture incorporates new algorithmic advancements in language modeling to balance speed and performance while allowing for quicker training times and iteration.
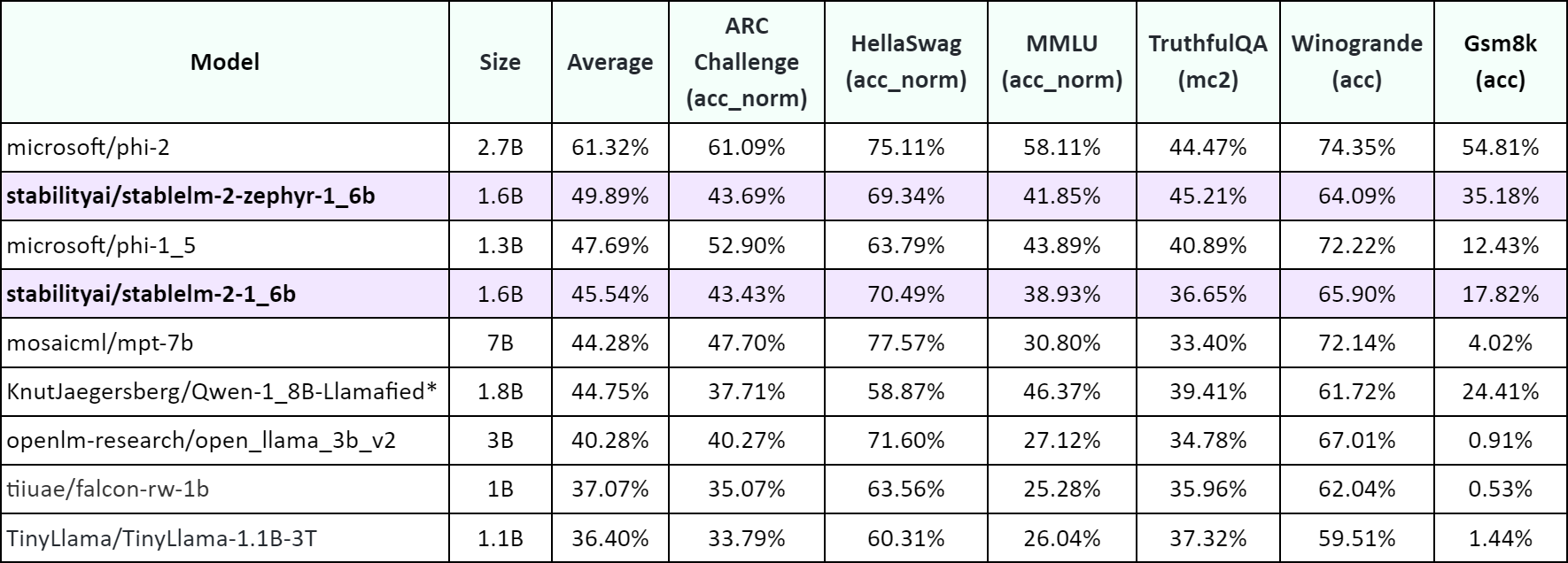
In the world of small language models, the Stable LM 2 1.6B is a standout performer. Benchmark results show it achieves state-of-the-art results for a model under 2 billion parameters. It outscored models like Microsoft's Phi-1.5 (1.3B), TinyLlama 1.1B, and Falcon 1B on the majority of tasks in the Open LLM Leaderboard.
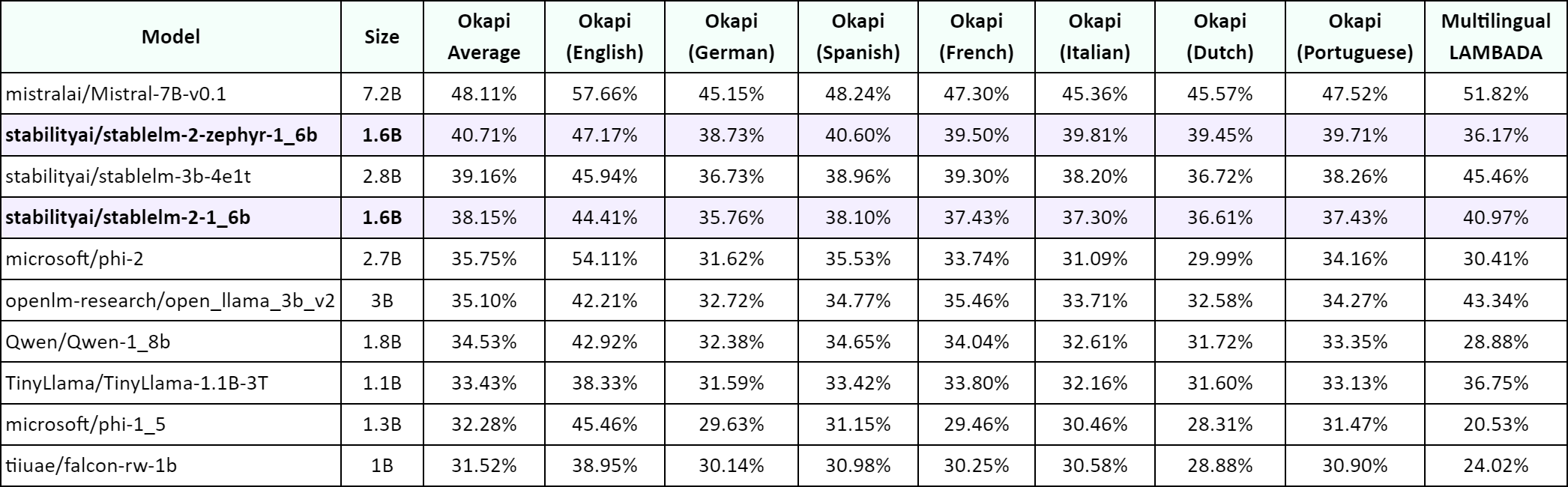
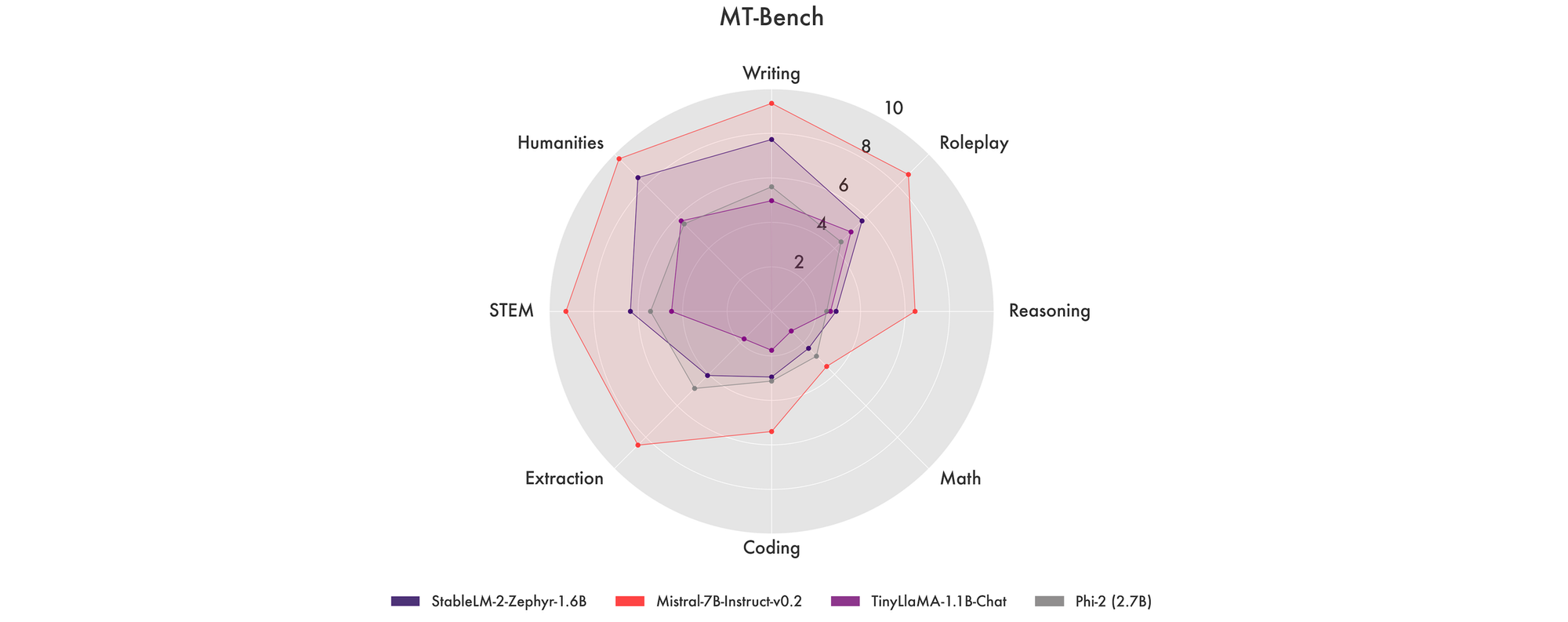
Thanks to its multilingual data, Stable LM 2 also delivered stronger accuracy on translated dataset versions from ARC, HellaSwag, TruthfulQA, and others. Additionally, the model's prowess is further illustrated in its MT Bench performance, where it shows competitive results, matching or even surpassing significantly larger models.
One of the most appealing aspects of the Stable LM 2 1.6B is its compact size and speed. This means significantly lower hardware requirements both for training and deployment. However, it is important to note that smaller models do have some drawbacks, such as increased hallucinations and decreased reasoning/other emergent capabilities. You can quickly test the model using the embedded Hugging Face Space below:
Stability AI has released the base model as well as an instruction-tuned version. The company has also provided the last checkpoint before the pre-training cooldown, complete with optimizer states. This transparency is a boon for developers looking to fine-tune and experiment with the model. The company says it will release a technical report that will provide more specifics on the data details and training procedures.