
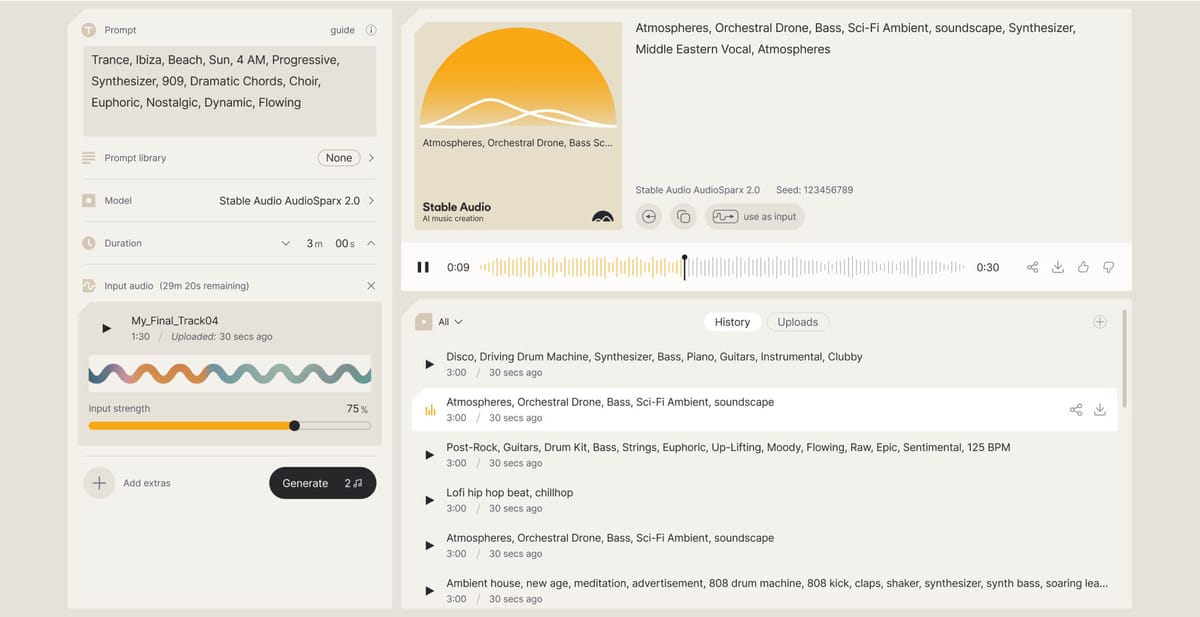
Stability AI has released Stable Audio 2.0, the newest version of their AI model that can generate music and sound effects. This latest iteration introduces a host of new features and capabilities, empowering artists and musicians to create high-quality, full-length tracks with unprecedented ease and flexibility.
One of the most remarkable advancements in Stable Audio 2.0 is its ability to generate songs up to three minutes in length, complete with structured compositions that include an intro, development, and outro, as well as stereo sound effects. This Sets Stable Audio 2.0 apart from other state-of-the-art models, as it can produce coherent musical structures that closely mimic human-composed tracks.
In addition to the text-to-audio functionality, Stable Audio 2.0 now supports audio-to-audio generation. Users can upload their own audio samples and transform them using natural language prompts, opening up a world of creative possibilities. This feature allows for the customization of the output's theme, aligning it with a project's specific style and tone.
The new model also enhances the production of sound and audio effects, from the tapping on a keyboard to the roar of a crowd or the hum of city streets. This capability offers new ways to elevate audio projects and create immersive experiences.
To achieve these impressive results, the Stable Audio 2.0 latent diffusion model has been specifically designed to enable the generation of full tracks with coherent structures. The architecture employs a new, highly compressed autoencoder that compresses raw audio waveforms into much shorter representations. For the diffusion model, a diffusion transformer (DiT), similar to that used in Stable Diffusion 3, is used in place of the previous U-Net, as it is more adept at manipulating data over long sequences.
Stability AI has also prioritized safeguarding creator rights and ensuring fair compensation. The model was exclusively trained on a licensed dataset from the AudioSparx music library, consisting of over 800,000 audio files. All of AudioSparx's artists were given the option to 'opt out' of the Stable Audio model training. Furthermore, to protect creator copyrights for audio uploads, Stability AI partners with Audible Magic to utilize their content recognition (ACR) technology to power real-time content matching and prevent copyright infringement.
If you want to check out more examples, there are two fun resources to explore:
- Stable Radio, a 24/7 live stream featuring tracks exclusively generated by the model, is now streaming on the Stable Audio YouTube channel.
- Stable Mixtape is an ever-evolvig curated playlist of tracks made by the Stable Audio community.
Stable Audio 2.0 is available to use for free on the Stable Audio website and will soon be accessible via the Stable Audio API. Stability AI says they will publish a research paper with additional technical details on the model in the future.