

Google AI has unveiled VideoPoet, a modeling method that can convert any autoregressive language model or large language model into a high-quality video generator. VideoPoet demonstrates state-of-the-art video generation, in particular in producing a wide range of large, interesting, and high-fidelity motions.
At its core, VideoPoet is a multitasker. From animating static images to editing videos for inpainting or outpainting, and even generating audio from video, its scope is vast. The model can take text, images, or videos as inputs, and its outputs span across text-to-video, image-to-video, and video-to-audio conversions, among others. This versatility positions VideoPoet as a comprehensive solution for various video generation tasks. A key advantage is that multiple capabilities are integrated within one model, eliminating the need for separate specialized components.
What sets VideoPoet apart is its reliance on discrete tokens for video and audio representation, akin to how LLMs process language. By employing multiple tokenizers (MAGVIT V2 for video and image, SoundStream for audio), VideoPoet can encode and decode these modalities into a viewable format. This approach allows the model to extend its language processing prowess into video and audio, making it a robust tool for creators and technologists alike.
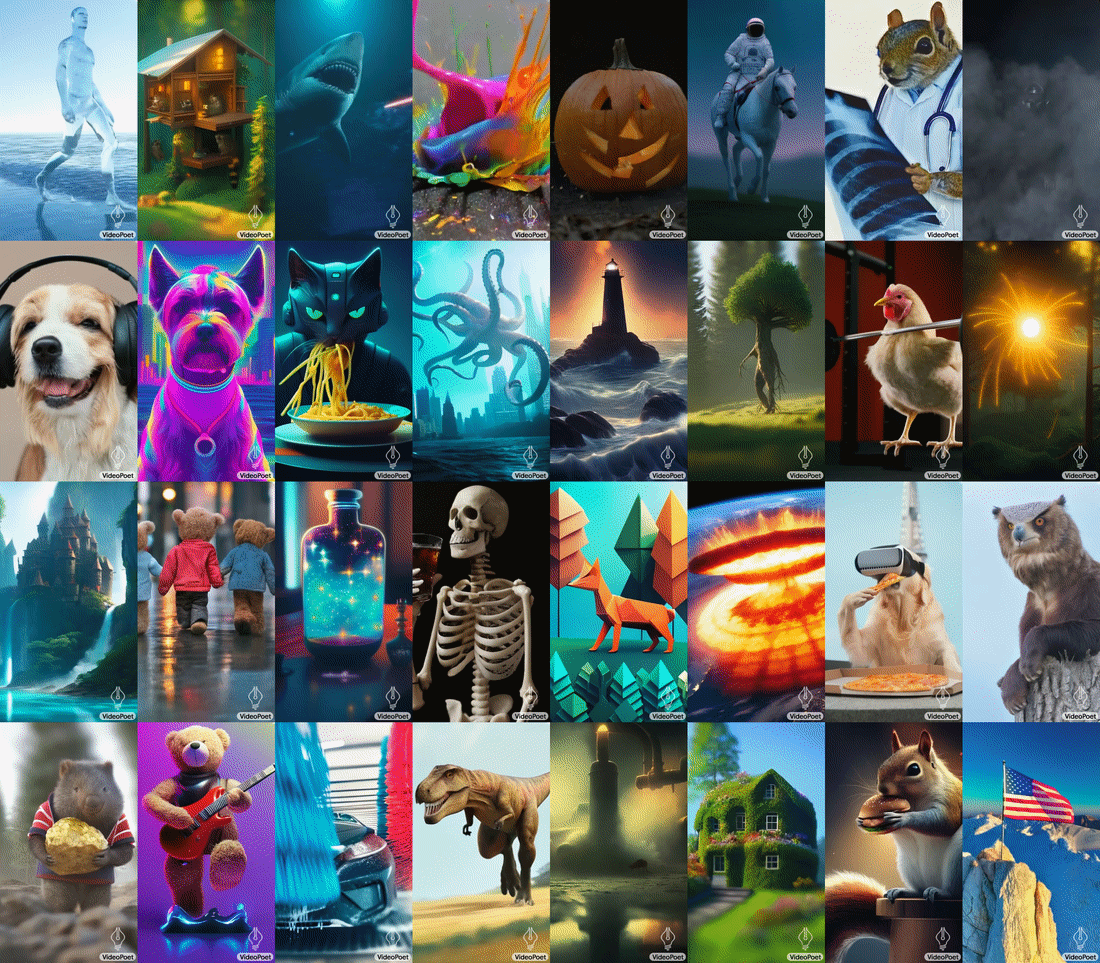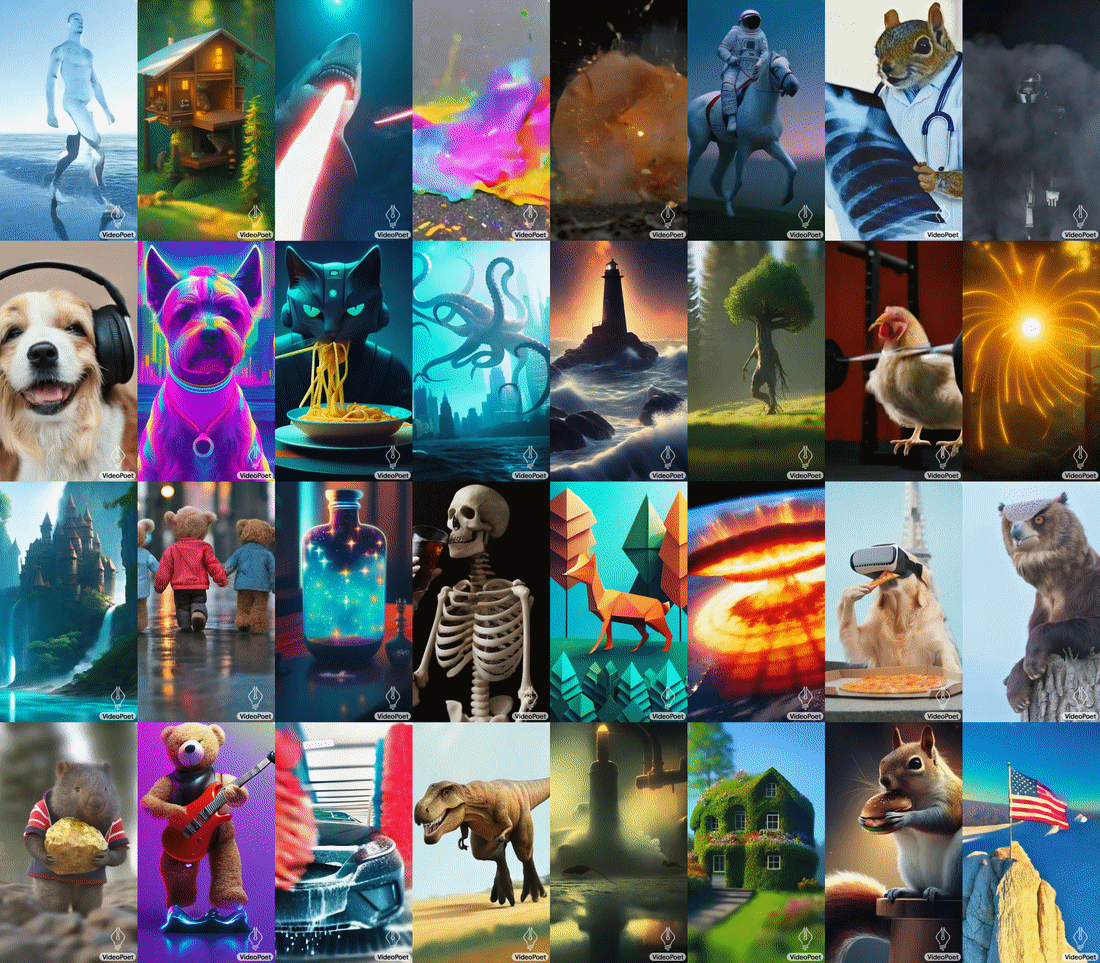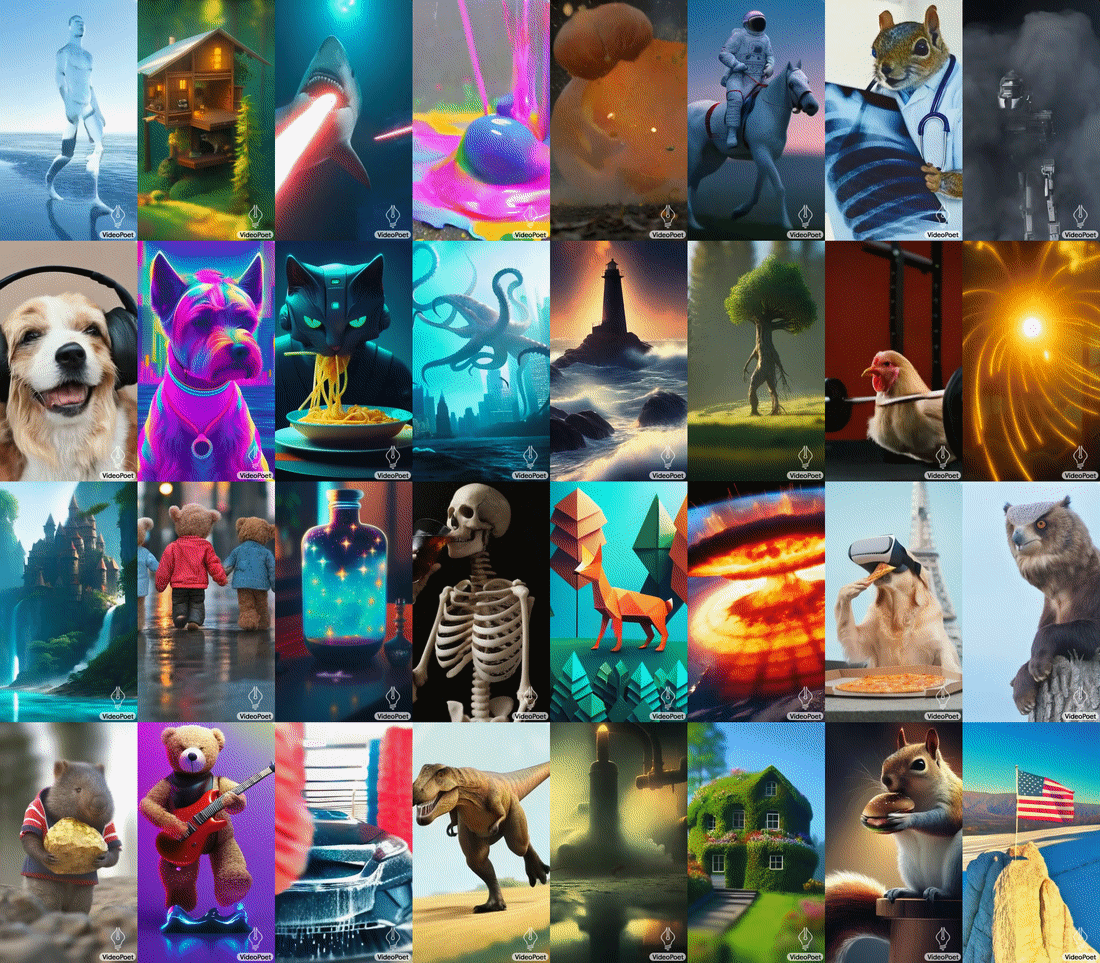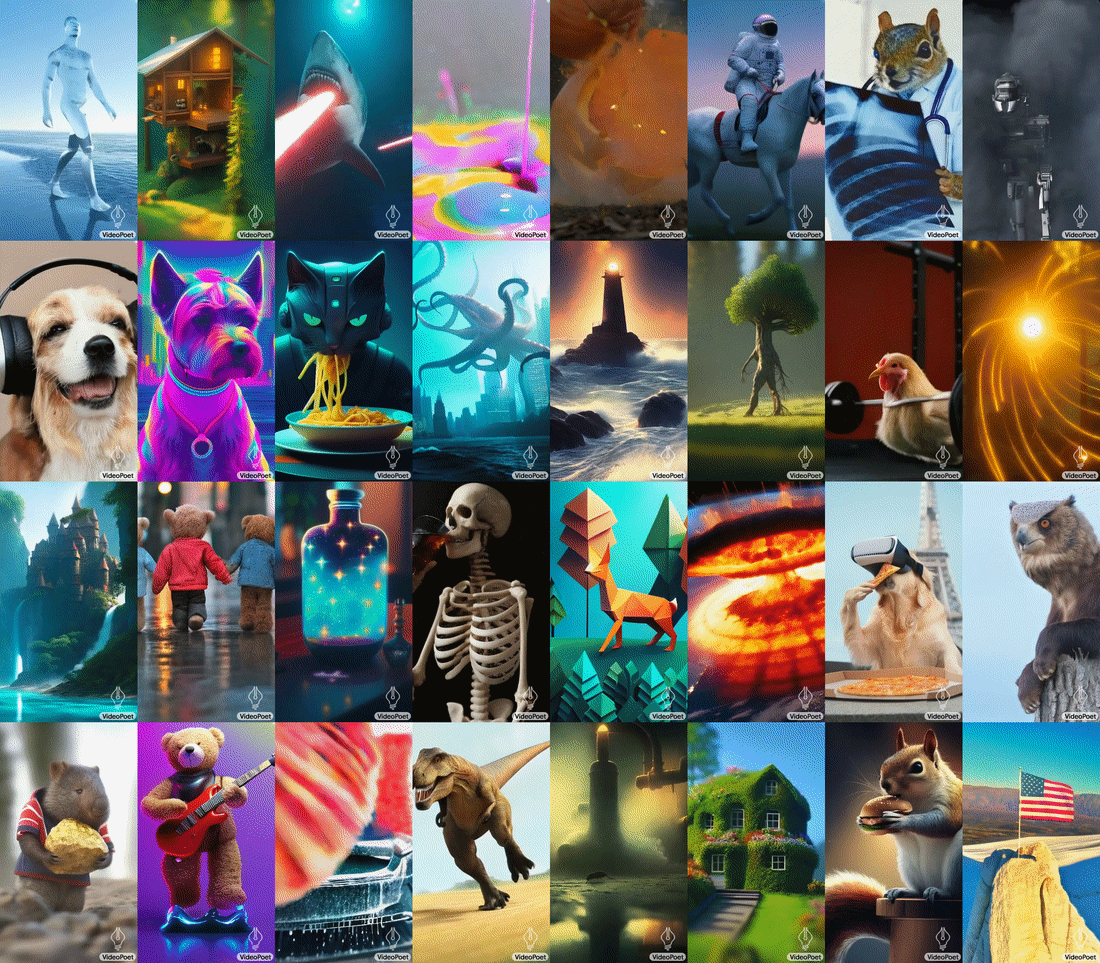
VideoPoet's capability to generate videos with diverse motions and styles, tailored to specific text inputs, showcases its advanced understanding of both content and context. Whether it's animating a painting or generating a video clip from a descriptive text, the model demonstrates a remarkable ability to maintain the integrity and appearance of objects, even over long durations. Google notes that the model supports generating videos in square orientation, or portrait to tailor generations towards short-form content, as well as supporting audio generation from a video input.

A notable feature of VideoPoet is its interactive video editing capability. Users can guide the model to modify motions or actions within a video, offering a high degree of creative control. The model can also accurately respond to camera motion commands, further enhancing its utility in creating dynamic and visually compelling content. Additionally, VideoPoet can also generate plausible audio for generated video without any guidance, demonstrating its excellent multimodal understanding.
By default, VideoPoet outputs 2-second videos. However, given a 1-second video clip, it can predict 1 second of video output. This process can be repeated indefinitely to produce a video of any duration.
While their output still lags considerably behind tools from Runway and Pika, VideoPoet highlights important progress that Google is making in AI-based video generation and editing.