

Large language models (LLMs) like Open AI's GPT and Google's PaLM can rapidly adapt to new tasks through a process called in-context learning (ICL), where the model is conditioned on a few examples to make predictions. However, ICL performance is highly sensitive to factors like the prompt template, label choices, and order of examples. This unpredictability has hindered the development of robust LLM applications.
Researchers at Google have shared a new technique, Batch Calibration (BC), that effectively mitigates these sensitivities. In their paper, they show that BC refines in-context learning, and effectively tackles many of its biases while delivering state-of-the-art performance and unprecedented robustness across a plethora of natural language understanding and image classification tasks.
One of the primary drivers behind BC’s creation was the aspiration to devise practical guidelines for ICL calibration. Current calibration methods, when dissected, revealed some gaps, notably in the issue of biased predictions—dubbed contextual bias. Addressing this, BC employs a linear decision boundary, known for its robustness, and refines the contextual bias estimation for each class, improving accuracy without increasing computational costs.

The key innovation of BC is using the unlabeled test set itself to estimate contextual bias in an LLM's predictions. This avoids introducing new biases that can occur when relying on additional "content-free" inputs. The research reveals deficiencies in prior methods like contextual calibration and prototypical calibration that use content-free tokens or random text as bias estimators. These fail for multi-text tasks like paraphrasing where inaccurate relations skew the estimation.
By aligning the score distribution to the estimated class means, BC recalibrates predictions to be less skewed by implicit biases in the prompt. It shifts the decision boundary away from the biased ICL boundary. BC is formulated as a simple additive correction to the LLM's log probabilities.
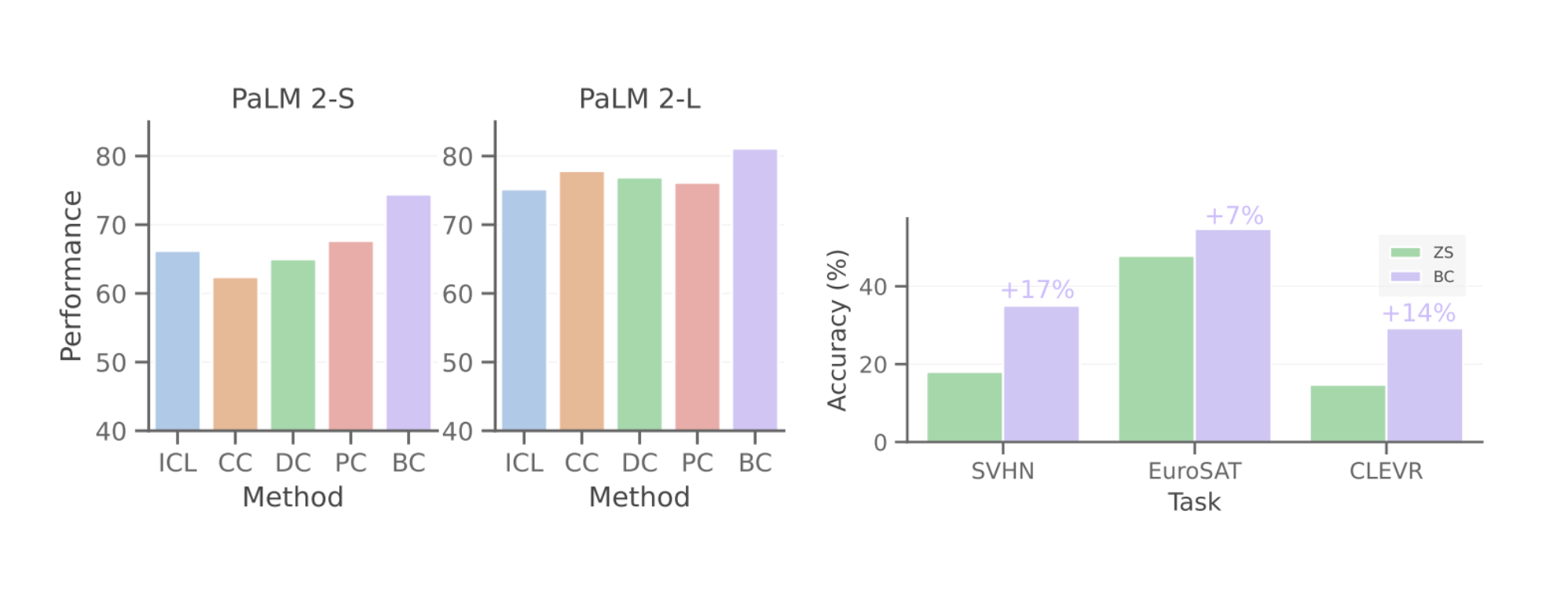
Across over 10 language and vision tasks, BC improved performance of PaLM 2 by 6-8% over uncalibrated ICL. It also outperformed prior calibration methods like contextual and prototypical calibration by 3-6%. Unlike those techniques, BC's improvements were consistent across all tasks evaluated including GLUE, SuperGLUE, and image classification benchmarks.
BC is zero-shot, requiring no training. Furthermore, its inference-only mechanism ensures that the added computational overhead is practically negligible. These properties make adoption effortless. BC was equally effective when applied to CLIP for image classification tasks, demonstrating its versatility across modalities.
Analyses revealed BC's robustness to choices in prompt design including example order, label space, and templates. This robustness will empower more accessible prompt engineering without expertise needed to finetune prompts.
Furthermore, a significant advantage of BC lies in its efficiency. While traditional methods like prototypical calibration necessitate extensive unlabeled datasets for stabilization, BC achieves commendable performance with just a handful of unlabeled samples. This sample efficiency will make calibration possible even in scenarios where there is limited data.
Overall, BC's remarkable consistency, generalizability, and robustness establish it as a simple plug-in solution to unlock greater performance from LLMs safely and stably. By effectively mitigating sensitivity to prompt engineering, Batch Calibration paves the way for more reliable deployment of LLMs to real-world applications.